Universitatea Tehnică din Cluj-Napoca
Facultatea de Automatică şi Calculatoare
Catedra de Automatică
Str. G. Bariţiu 26-28, 400027 Cluj-Napoca, ROMÂNIA
Tel.: +40-264-594469
Fax/Tel.: +40-264-594469
CONTRACT TIP PN-II-IDEI, nr. 93/1.10.2007
Faza I, unică pe anul 2007
Valoare fază: 53.412 lei
Prezentare detaliată
Dezvoltarea unor capacităţi de auto-întreţinere pentru societăţi digitale
Faza 2007 - Adunarea şi sistematizarea datelor existente privind societatea digitală.
Activităţi:
1. Analiza de sistem pentru societatea digitală.
2. Cauzele şi factorii care influenţează evoluţia societăţii digitale.
1. Arhitecturi software
1.1. Ce este o arhitectură?
Arhitectura a devenit o componentă crucială a procesului de design al unui sistem.
Arhitectura software acoperă întreaga funcţionalitate şi legăturile între componentele sistemelor software de mari dimensiuni. O privire din punct de vedere al arhitecturii, asupra unui sistem, este abstractă, dezvăluind detalii de implementare, algoritmi şi structuri de date, dar concentrându-se pe interacţiunea şi funcţionalitatea componentelor stabilite (privite la şi „black boxes”).
Bass [1] include o reprezentare tipică a unei structuri software, şi o analizează la prima vedere, stabilind următoarele aspecte pe care le putem afirma din această reprezentare:
Figura 1.1.1. - Un caz tipic de reprezentare a unei arhitecturi software [1]
· Sistemul are 4 elemente.
· Trei dintre elemente (cele de pe nivelul inferior) pot avea mai multe în comun, între ele, decât cu cel de-al patrulea element, deoarece sunt poziţionate unul lângă altul.
· Fiecare element are o anumită legătură cu celelalte, deoarece diagrama este complet-conectată.
Ne punem întrebarea: este aceasta o arhitectură software? Dacă ar fi să presupunem (cum o fac multe definiţii) că arhitectura este o mulţime de componente (patru în cazul nostru) şi legăturile între ele (care sunt cuprinse în diagramă), atunci răspunsul la întrebare ar fi da. Chiar dacă ne ghidăm după cele mai îngăduitoare definiţii, există anumite aspecte care nu pot fi clarificate din această figură, şi anume:
· Ce reprezintă aceste elemente? După ce principii au fost separate? Rulează în paralel? Reprezintă obiecte, funcţii, procese?
· Care este funcţionalitatea acestor elemente?
· Ce reprezintă legăturile între ele? Legăturile reprezintă comunicare între elemente? Sunt legături de control? Legături de sincronizare? O combinaţie între acestea? Ce informaţii se schimbă între fiecare elemente?
· Ce reprezintă această organizare? De ce un element este pe un alt nivel decât celelalte? Comunicarea este doar de la nivelele superioare spre cele inferioare?
Tot Bass [1] afirmă că „arhitectura software a unei aplicaţii sau sistem informatic este structura sau structurile din sistem, care cuprind elemente software, caracteristicile externe ale acestor elemente şi relaţiile dintre ele”. Prin caracteristici externe, se înţeleg caracteristicile pe care alte elemente pot presupune că le are elementul în cauză, cum ar fi serviciile oferite, indici de performanţă, toleranţa la defecte, utilizarea resurselor comune, etc.
Putem analiza mai în detaliu această definiţie.
Pentru început, arhitectura defineşte elemente software. Arhitectura cuprinde informaţii legate de cum interacţionează elementele între ele. Aceasta poate duce la omiterea intenţionată a elementelor care nu au de a face cu funcţionalitatea celorlalte elemente. Astfel, se poate spune că arhitectura este o abstractizare a unui sistem care restricţionează detaliile elementelor pentru care nu este important cum folosesc, sunt folosite, se leagă sau interacţionează cu celelalte elemente. În majoritatea sistemelor moderne, elementele interacţionează prin intermediul interfeţelor care partajează detaliile elementelor în private şi publice. Arhitectura se concentrează pe partea publică a acestor interfeţe – detaliile private, care au de-a face strict cu implementarea internă, nu ţin de arhitectură.
Definiţia lui Bass [1] clarifică faptul că un sistem poate şi chiar cuprinde mai mult decât o singură structură software şi nu se poate ca o structură, singură, să fie considerată arhitectură. De exemplu, fiecare proiect, cu un anumit nivel de complexitate, este impărţit în mai multe faze şi task-uri; fiecare fază are stabilite activităţile şi rezultatele cuprinse şi, de cele mai multe ori, este baza de lucru pentru echipele de implementare. O astfel de fază sau task cuprinde, pe de o parte, date şi software care pot fi accesate de alte echipe sau pot fi folosite în alte faze, iar pe de altă parte, date private, interne. În proiectele mari, pentru o fază există mai multe echipe/sub-echipe care se ocupă de taskurile prevăzute. Acest tip de structură este asemănător cu o structură folosită pentru descrierea unui sistem software. Se poate spune că este static în felul în care funcţionalitatea sistemului este descompusă şi împărţită la echipele de implementare. Alte structuri se vor concentra mai mult pe felul în care componentele interacţionează între ele, în timpul rulării sistemului, pentru a asigura funcţionalitatea specificată.
Tot din definiţie reiese faptul că orice sistem informatic se bazează pe software şi implicit are o arhitectură software, deoarece orice sistem poate fi definit ca şi cuprinzând mai multe elemente şi relaţiile dintre ele. În cel mai banal caz, un sistem este el în sine un element component – un caz care nu prezintă nici un interes şi care, probabil, nu este de mare folos, dar, fără îndoială, este o arhitectură. Deşi fiecare sistem are o arhitectură, nu este exclus faptul ca nimeni să nu aibă toate detaliile legate de acea arhitectură. Poate toţi cei care au contribuit la structura sistemului au plecat, documentaţia nu mai este la îndemână (sau poate nu a fost niciodată creată), codul sursă s-a pierdut (sau nu a fost livrat), şi tot ce a rămas este codul executabil, funcţional. Acest caz face diferenţa între arhitectura sistemului şi efectiv reprezentarea acestei arhitecturi. Din păcate, o arhitectură poate exista independent de descrierea sau specificaţiile ei, ceea ce ridică problema documentării arhitecturii software şi re-formarea arhitecturii.
Funcţionalitatea fiecărui element face parte din arhitectură, până la punctul în care aceasta poate fi observată sau stabilită din contextul altui element. Un astfel de comportament permite elementelor să interacţioneze între ele, ceea ce am stabilit că face clar parte din arhitectură. Acest aspect vine în sprijinul afirmaţiei că „liniile şi casetele din reprezentarea arhitecturilor software nu sunt sub nici o formă arhitecturi. Ele sunt simple linii şi casete, ele servesc ca puncte de reper, pentru a oferi informaţii despre ce face fiecare element reprezentat” (Figura 1). Nu se presupune că funcţionalitatea exactă a fiecărui element trebuie documentată în detaliu, în toate cazurile; totuşi, având în vedere faptul că funcţionalitatea unui element afectează felul în care alt element trebuie implementat pentru a interacţiona cu el, sau influenţează compatibilitatea sistemului ca întreg, această funcţionalitate este parte din arhitectură.
Definiţia pasivă legat de „calitatea” arhitecturii – este o arhitectură bună sau nu. Un mecanism „trial-and-error” nu este acceptabil pentru alegerea arhitecturii pentru sistemul nostru software, adică alegerea unei arhitecturi aleator, implementarea sistemului software, si testarea rezultatului. Aici apare nevoia şi importanţa conceperii arhitecturii şi evaluării arhitecturii.
1.2. Alte puncte de vedere
Domeniul arhitecturilor software e în continuă dezvoltare, de aceea nu există o singură definiţie universal acceptată. Există mai multe definiţii, multe dintre ele mergând pe aceleaşi idei legat de structură, elemente şi legăturile dintre ele, detaliile structurale diferind de la o definiţie la alta. Este de dorit să înţelegem definiţiile des întâlnite în comunitatea ingineriei software pentru că este foarte probabil să le întâlnim şi atunci să putem să le discutăm şi să analizăm implicaţiile lor.
· Arhitectura este un design de nivel superior. Această definiţie poate fi adevărată dar nu şi reciprocă: diferite caracteristici ale designului software nu sunt arhitecturale, cum ar fi stabilirea tipurilor de date încapsulate; interfaţa acestor tipuri de date ţine de arhitectură, dar nu şi alegerea efectivă a acestor date.
· Arhitectura consistă din structura întregului sistem software. Definiţia afirmă că un sistem software are o singură structură, ceea ce este incorect. Acest punct de vedere are mai mult decât o importanţă teoretică sau pedagogică, diferitele structuri implicate vor sta la baza superiorităţii unei arhitecturi software, aceste structuri conţinând cheia conceptului de arhitectură software.
· Arhitectura reprezintă structura componentelor unui sistem software, relaţiile dintre ele, principiile şi direcţiile dominante legate de designul şi funcţionalitatea lor. Orice sistem software are o arhitectură care poate fi analizată independent de funcţionalitatea şi procesele pentru care a fost creată. De aceea, „principiile şi direcţiile dominante de designul şi funcţionalitatea lor” se referă la nişte informaţii care pot fi dovedite a fi esenţiale şi un semn de bună practică, dar totuşi, nu se pot considera ca fiind parte integrantă din arhitectură.
· Arhitectura se referă la componente şi conectori. Conectorii implică un mecanism funcţional de transfer al datelor şi comenzilor; putem concluziona că definiţia se leagă de arhitecturi funcţionale. În definiţia discutată anterior, descompunerea arhitecturii în componente responsabile de anumite funcţionalităţi duce la asignarea termenului de „static” sau „non-funcţional” acelei arhitecturi. Când vorbim de relaţiile între componente, trebuie să suprindem atât aspectul funcţional cât şi cel static al componentelor.
La baza discuţiilor despre arhitectura software este analiza aspectelor structurale ale sistemului softare. Şi deşi arhitectura este de multe ori folosită pentru a reprezenta un şablon funcţional, ca şi client-server, este de cele mai multe ori folosită pentru a descrie aspectele structurale ale unui anumit sistem. Această idee am încercat să o cuprindem în analizele diferitelor definiţiile despre arhitectură.
1.3. Determinarea caracteristicilor sistemului software pe baza arhitecturii
Apare un semn de întrebare legat de posibilitatea de a determina, înainte ca sistemul să fie pus în funcţiune, dacă anumite caracteristici cerute vor fi disponibile într-un sistem software? Dacă nu ar exista această posibilitate, alegerea unui arhitecturi s-ar face după o selecţie aleatoare. Există posibilitatea de a analiza caracteristicile unui sistem doar pe baza arhitecturii lui software. Bass [1] descrie în Capitolul 11 metoda ATAM (Architecture Tradeoff Analysis Method), pe care nu o vom discuta pe larg în această lucrare, însă vom reţine câteva idei legate de relaţiile dintre elemente şi caracteristicile sistemului software rezultat:
· Dacă performanţa este o caracteristică importantă a sistemului software, atunci trebuie gestionată foarte bine funcţionalitatea temporală a componentelor şi frecvenţa şi volumul datelor transmise între ele.
· Dacă este nevoie de flexibilitate în structură, funcţionalitatea elementelor trebuie aleasă în aşa fel încât consecinţele modificărilor structurale să fie locale.
· Dacă sistemul software trebuie să fie foarte bine securizat, se va monitoriza şi proteja schimbul de informaţii între elemente şi se va stabili care elemente vor avea acces la diferite informaţii. Există posibilitatea să fie nevoie de elemente specializate pentru anumite date sensibile.
· Dacă scalabilitatea este un factor important, utilizarea resurselor trebuie făcută local, pentru a facilita introducerea unor noi elemente.
· Dacă se doreşte re-utilizarea anumitor componente şi în alte sisteme, cuplarea elementelor trebuie restricţionată astfel încât, un element să poată fi izolat fără a fi nevoie de prea multe elemente ataşate în noul sistem.
Strategiile pentru asigurarea acestor (şi ale altor) caracteristici sunt fără îndoială de natură arhitecturală. Este important de reţinut totuşi, că doar arhitectura nu poate garanta funcţionalitatea sau calitatea sitemului software. O implementare sau decizii de implementare nepotrivite pot oricând afecta negativ un design arhitectural potrivit. Deciziile de la fiecare nivel – începând de la designul arhitectural la implementare şi programare – afectează calitatea sistemului software rezultant.
Aşadar, calitatea unui sistem software nu ţine doar de arhitectura sa. Pentru a asigura calitatea este nevoie e o arhitectură potrivită, dar nu este suficient.
1.4. Arhitecturi dependabile
Am văzut în definiţiile analizate anterior aspectele esenţiale ale arhitecturii software pentru un sistem software. Este mult mai greu însă să demonstrăm că o arhitectură este dependabilă. Pe lângă detaliile sistemului, definiţia dependabilităţii sistemului software trebuie să includă şi funcţionalitatea în diferite contexte ale componentelor software în contextele lor, conform încadrării arhitecturale.
În lucrarea sa, Kittusamy [2] defineşte arhitectura dependabilă pentru un sistem software ca fiind „arhitectura software care îndeplineşte cerinţele de bază pentru care a fost concepută şi îndeplineşte obiectivele de comunicare specificate”.
Măsurarea dependabilităţii este un proces complicat, dar este posibil să definim criterii pentru stabilirea dependabilităţii unei arhitecturi software într-un context funcţional dat. Software-ul este extrem de flexibil în ceea ce priveşte configurarea şi implementarea sa; aceste avantaje îi vor oferi un rol major în asigurarea unui nivel ridicat de dependabilitate pentru o aplicaţie.
În discuţia despre dependabilitate este foarte important să discutăm despre defecte şi erori în funcţionalitate. Sunt mulţi factori care pot duce la erori. Cele mai des întâlnite cazuri se datorează defectelor structurale sau de concepere ale sistemului software. Există des întânitele cazuri când erorile se datorează defectelor din etapa de implementare. Ca exemple, erorile de configurare, estimări greşite în transmisia datelor, interfeţe netestate corespunzător, erori de integrare – toate acestea reprezintă defecte arhitecturale care pot duce la eşecul sistemului software.
Jackson [3] aduce în discuţie posibilitatea ca „eşecul unui sistem software să fie datorat mediului în care acesta funcţionează. Orice sistem software care interacţionează cu mediul extern al aplicaţiei (software şi de altă natură) este vulnerabil la varietatea şi noile situaţii pe care mediul le generează”. Jackson [3] mai adaugă că, „dezvoltarea unui sistem software reuşit depinde de identificarea şi analizarea situaţiilor care se dovedesc a fi importante” şi la care acel sistem este posibil să fie expus; de asemenea trebuie luate decizii privind caracteristicile şi funcţionalitatea sistemului în astfel de situaţii pentru a le face faţă eficient. Aceste afirmaţii readuc în atenţie importanţa proceselor de implementare şi configurare a sistemului software.
1.4.1. Asigurarea dependabilităţii prin adaptare flexibilă
Pentru a asigura un grad ridicat de dependabilitate sistemului software, adaptarea flexibilă la schimbări este critică. După Wermelinger [4], „pentru a permite schimbări globale la nivelul regulilor de funcţionare sau proceselor, o arhitectură software dependabilă va permite două tipuri de modificări”.
Primul tip este cel legat de nivelul aplicaţie, în care sunt implicaţi utilizatorii aplicaţiei. Ei nu au cunoştinţe tehnice, dar respectând anumite reguli de aplicaţie ei pot continua lucrul în limitele specificaţiilor tehnice impuse de arhitectura software dependabilă.
Al doilea tip implică sistemul software. Acest tip se adresează celor care implementează sistemul software, şi care vor avea nevoie să modifice funcţionalitatea iniţială fără a schimba implementarea arhitecturală.
Wermelinger [4] este de părere că pentru a permite cele două tipuri de modificări, „arhitectura software dependabilă ar trebui să implice ‘nivele de configurare’”. Procesul de configurare va asigura faptul că sistemul software se va dezvolta în anumite limite şi restricţii, care ţin de aplicaţie sau de arhitectura sistemului. Tehnic vorbind, adaptarea flexibilă la schimbare este asigurată prin două modalităţi.
· Prima este parametrizarea regulilor aplicaţiei, definiţiile acestora folosind parametrii care vor permite configurarea funcţionalităţii aplicaţiei. Parametrii pot fi combinaţi pentru a obţine o prioritizare a regulilor de acelaşi tip.
· A doua modalitate se adresează la nivelul rulării aplicaţiei. Între datele transmise şi componenta destinaţie intervine o componentă de configurare care va parametriza datele transmise, astfel că acestea vor fi afectate de regulile aplicaţiei, chiar şi după modificările permise.
Aşadar, pentru ca o arhitectură software să fie dependabilă, o caracteristică necesară este adaptarea flexibilă la schimbare.
1.4.2. Arhitectura „de supravieţuire”
Arhitecturile software de nivel enterprise sunt deseori de dimensiuni mari şi un grad mare de complexitate, fiind nevoie de echipe întregi de arhitecţi şi analişti software pentru a le înţelege. Cu această complexitate copleşitoare apare un mare risc să se strecoare erori nedetectate, şi aici apare nevoia pentru o arhitectură „de supravieţuire”.
Una dintre definiţiile acceptate [5] este: „o proprietate a unui sistem, sub-sistem, echipament, proces sau procedură care furnizează un anumit nivel de certitudine că entitatea respectivă va funcţiona în timpul şi după o intervenţie umană”. Pentru o anumită arhitectură software, factorul de supravieţuire trebuie definit prin specificarea setului de condiţii la care sistemul le va tolera, nivelul minim de funcţionalitate garantat după intervenţia umană şi durata maximă suportată de perturbaţii.
Prin definiţia anterioară, conform lui Knight [6], o arhitectură software dependabilă este „de supravieţuire” dacă respectă specificaţiile de mai sus. Unii consideră chiar supravieţuirea sistemului ca fiind unul şi acelaşi lucru cu dependabilitatea, dar conform [6], o vom considera doar un factor important în asigurarea dependabilităţii unei arhitecturi software.
1.4.3. Toleranţa la defecte
O metodă dovedită pentru a avea o arhitectură dependabilă care va face faţă defectelor, este un design arhitectural cu toleranţă la defecte. Specificaţiile de supravieţuire ale sistemului software nu trebuie totuşi să corespundă cu cele ale designului tolerant la defecte. Rolul arhitecturii „de supravieţurile”, este după Knight şi Strunk [7] să ofere contextul la nivel de sistem pentru implementarea toleranţei la defecte, necesare pentru îndeplinirea obiectivelor de supravieţuire ale sistemului.
Se mai conturează altfel o caracteristică esenţială a arhitecturilor dependabile, şi anume: arhitecturile dependabile trebuie să aibă integrate mecanisme care să le ofere capabilitatea de a face faţă în mod tolerant defectelor. Chiar dacă unele sub-sisteme îşi încetează funcţionalitatea, în mod parţial sau total, sistemul software în ansamblu continuă să pună la dispoziţie celelalte servicii neafectate, prin intermediul celorlalte sub-sisteme funcţionale. Un eşec total al sistemului este o situaţie excepţională pentru un sistem software capabil de a tolera defectele, care respectă specificaţiile de supravieţuire discutate anterior.
Pentru ca un sistem să aibă capabilitatea de a tolera defectele, Kittusamy [2] recomandă o abordare „Reconfiguration-Based Fault-Tolerance”, adică o toleranţă a defectelor pe bază de reconfigurare.
1.4.4. Reconfigurarea
Reconfigurarea poate fi definită ca şi o schimbare de origine arhitecturală a configuraţiei sistemului software în timpul funcţionării acestuia. Porcarelli [8] identifică două tipuri de reconfigurări, în funcţie de nivelul la care apare schimbarea:
1. Reconfigurare la nivel de componentă – „orice schimbare a parametrilor de configurare a uneia sau mai multor componente”.
2. Reconfigurare la nivel arhitectural – „orice schimbare în topologia aplicaţiei, legată de numărul sau rolul componentelor software”.
Reconfigurarea la nivel de componentă (tipul 1) este recomandată când modulele software sau subsistemele software nu sunt strâns interconectate şi nu sunt dependinţe între ele.
Pe de altă parte, tipul 2 de reconfigurare – arhitectural – este recomandat în cazul unor dependinţe critice între modulele sau subsistemele software.
Reconfigurarea necesită prezenţa unor funcţionalităţi şi mecanisme integrate în acest proces. Pentru început, reconfigurarea necesită o monitorizare a sistemului software pentru a detecta defectele sau erorile la nivel de componentă sau la nivel de sistem. Procesul de reconfigurare trebuie abordat în ideea în care se pot trata defectele apărute iar sistemul poate fi readus la un nivel de funcţionalitate prevăzut pentru acest caz. Reconfigurarea în timpul funcţionării sistemului presupune pre-stabilirea unor parametrii, reguli şi mecanisme legate de sistemul software; aceste reguli şi mecanisme trebuie stabilite având în vedere toate cazurile posibile de defecte sau erori. De asemenea, trebuie stabilit şi un set de reguli şi mecanisme pentru cazurile neprevăzute. Este foarte posibil ca erorile neprevăzute să necesite în final o reconfigurare la nivel arhitectural.
1.4.5. Criterii de evaluare
A stabili şi a demonstra că un sistem software are o arhitectură dependabilă este un proces extrem de complex. Se poate evalua totuşi cât de bine un sistem software sau o familie de sisteme software respectă unele dintre criteriile pentru o arhitectură software dependabilă. Următoarele criterii sunt întâlnite la mai mulţi autori şi sunt bazate pe o abordare pragmatică a evaluării arhitecturale. Multe dintre proprietăţile sistemelor software discutate până la acest capitol pot fi identificate şi validate folosind aceste criterii.
· În urma unei analize critice a arhitecturii sistemului software a reieşit că sistemul software îndeplineşte cerinţele de dependabilitate pentru un anumit task sau aplicaţie.
· Detaliile tehnice ale arhitecturii sistemului software prezintă caracteristicile unui sistem stabil, nivele funcţionale uşor de separat, componente software bine definite şi o inter-conectabilitate bine definită.
· Unele componente software sunt re-utilizate, adică mai multe alte componente le utilizează.
· Modelul de implementare al sistemului software se aliniază standardelor recunoscute în domeniu. De asemenea, cele mai bune practici au fost clar specificate şi optimizate pentru domeniul în care va funcţiona sistemul software.
Dezvoltările ulterioare ale sistemului software şi implicit ale arhitecturii sale, preconizează o tehnologie de vârf în domeniu; mai mult, planurile arhitecturale viitoare prezintă multe din caracteristicile unei arhitecturi software dependabile.
1.5. Elaborarea arhitecturii
Grady Booch spunea: „La toate sistemele de succes orientate pe componente cu care am lucrat, am observat două caracteristici, cărora li se simţea lipsa în sistemele pe care le considerăm nereuşite: existenţa unei viziuni arhitecturale clar definite şi aplicarea unui ciclu de dezvoltare incremental şi bine organizat pe etape.”
În capitolele anterioare am descris nevoile care stau la baza unei arhitecturi software, prin prezentarea unor principii şi concepte, structuri şi atribute.
În acest capitol ne vom concentra atenţia asupra elaborării unei arhitecturi şi paşilor care trebuie urmaţi.
1.5.1. Arhitectura în ciclul de viaţă al unui sistem software
Bass [1] afirmă că “o organizaţie care se acceptă arhitectura ca şi fundaţia procesului de dezvoltare software, trebuie să-i înţeleagă rolul în ciclul de viaţă al acelui sistem.” Există mai multe modele pentru acest lucru, dar cel care dă un echilibru arhitecturii şi dezvoltării software este Evolutionary Delivery Life Cycle model, adică un model bazat pe livrări incrementale ale sistemului software. Acest model este prezentat în Figura 1.5.1.1.
Scopul acestui model este de a strânge feedback de la utilizatorii finali şi a-l încorpora în mai multe livrări intermediare, înainte de livrarea finală. Modelul permite adăugarea de noi funcţionalităţi la fiecare iteraţie şi livrarea unei versiuni de test în momentul în care au fost integrate un număr semnificativ de modificări.
Procesul descris începe prin strângerea cerinţelor preliminare şi analizarea lor, fără de care nu se poate începe analizarea sistemului. Această etapă nu trebuie să strângă o mulţime exhaustivă de cerinţe, procesul poate continua cu o mulţime iniţială de cerinţe.
Arhitectura se elaborează ţinând cont de o serie de cerinţe funcţionale, de calitate şi specifice scopului care urmează să-l servească, numite şi business requirements. Aceste cerinţe după care se mulează arhitectura se numesc cerinţe arhitecturale (architectural drivers). Pentru determinarea cerinţelor arhitecturale nu există o reteţă universală. Bass [1] recomandă să începem cu cerinţele specifice cele mai importante, care ar trebui să aibă un număr redus; dintre acestea, se vor alege cele care vor avea cel mai mare impact asupra arhitecturii. Rezultatul poate fi declarat mulţimea cerinţelor arhitecturale şi, de obicei, numărul lor ar trebui să fie sub zece.
Odată identificate cerinţele arhitecturale, procesul de design arhitectural poate începe. Procesul de analiză a cerinţelor poate fi influenţat în continuare de întrebările şi problemele ridicate în etapa de design arhitectural (din elaborarea arhitecturii), fapt indicat şi în Figura 2 prin săgeţile inverse, la procesele anterioare.

Figura 1.5.1.1. - Evolutionary Delivery Life Cycle [1]
1.5.2. Elaborarea arhitecturii
O metodă de definire a arhitecturii care satisface criteriile de evaluare a arhitecturii cât şi cerinţele funcţionale este descrisă pe larg de Bass [1]. Această metodă este numită Attribute-Driven Design (definirea arhitecturii tinând cont de caracteristicile acesteia), notată ADD. ADD porneşte de la un set de caracteristici iniţiale şi pe baza cunoştinţelor legate de relaţia dintre implementarea acestor caracteristici şi rezultatul arhitectural final, se va defini arhitectura.
Abordarea ADD în definirea arhitecturii se bazează astfel pe caracteristicile specificate pentru a descompune sistemul software în funcţie de funcţionalităţile pe care trebuie să le implementeze. Este un proces de modularizare repetitiv, la fiecare pas analizându-se pattern-urile arhitecturale care satisfac caracteristicile specificate, funcţionalitatea fiind apoi alocată tipurilor de module rezultate în urma aplicării pattern-urilor arhitecturale. ADD apare în ciclul de elaborare a arhitecturii după analizarea cerinţelor şi poate începe după ce cerinţele arhitecturale au fost stabilite cu o oarecare siguranţă.
Rezultatele metodei ADD sunt primele iteraţii de descompunere în module cât şi alte aspecte legate de acestea, unde este cazul. Nu toate detaliile unui iteraţii sunt rezultatele aplicării ADD; sistemul software este descris ca şi o mulţime de componente funcţionale şi interacţiunile dintre ele. Acesta este primul stadiu rezultat al procesului de definire a arhitecturii şi este esenţial în obţinerea caracteristicilor specificate. Totodată constituie un ansamblu de bază funcţional pentru viitorul sistem software.
Diferenţa dintre o arhitectură rezultată în urma aplicării ADD şi una care poate intra în procesul de implementare o constituie detalierea deciziilor arhitecturale luate în procesul de descompunere în module a arhitecturii. Acestea pot fi de exemplu decizii de a folosi anumite pattern-uri object-oriented sau de a integra un modul intermediar dezvoltat de altcineva, care poate impune multe restricţii arhitecturale. Arhitectura rezultată în urma aplicării ADD poate intenţionat lăsa nespecificate aceste decizii pentru a mări gradul de flexibilitate finală.
Bass exemplifică în detaliu metoda ADD în [1], Capitolul 7.2, paginile 171-179.
2. Sisteme cu auto‑întreţinere
În sistemele de calcul de azi, puterea de calcul nu mai este concentrată în câteva unităţi complexe si scumpe, ci în multe unităţi simple şi ieftine. Puterea lor constă în colaborare. Ele au şi avantajul unei fiabilităţi şi flexibilităţii ridicate. Pot exista unităţi de rezervă, gata să „se prezinte” oricând se defectează unul în lucru.
De exemplu, NASA lucrează la „roiuri” de vehicule robotice pentru explorarea spaţiului în viitor [9]. Aceste roiuri au avantajul autogestionării şi supravieţuirii. Dezavantajul constă în proiectarea şi programarea lor complexă. Agenţia a pornit lucrările la ANTS (Autonomous Nanotechnology Swarm - Roi Autonom cu Nanotehnologie) [10], o misiune‑concept, analizând diverse modele din punct de vedere al comportamentului aşteptat al roiului.
O altă echipă de cercetare, de la Syracuse University, NY, SUA, lucrează la organizarea şi coordinarea unui număr mare de agenţi simpli distribuiţi într‑un sistem, ca să obţină, în cuvintele lor, „un comportament global în dezvoltare dorit” [11]. Ei intenţionează să folosească tehnologia într‑o abordare distribuită în reducerea defectărilor într‑un sistem de scară largă de achiziţie a datelor pentru BTeV, un experiment de Fizica Energiei („High Energy Physics”) bazate pe un accelerator de particule, în dezvoltare la Laboratorul Acceleratorului Naţional Fermi. Ei au nevoie de capacităţile distribuite ale roiului din cauza cantităţii mari de date care trebuie transferate şi analizate – peste un teraoctet în fiecare secundă, distribuit prin 2500 procesoare digitale de semnal. Rezultatele lor de simulare arată cum agenţi polimorfici uşori înglobaţi în procesoarele individuale folosesc teorii de joc pentru a se adapta mediului.
IBM îşi creşte eforturile de cercetare în calculul autonom [12]. Ei spun ca acesta trebuie să ofere un nivel nemaiîntâlnit de auto‑reglaj, în timp ce ascunde complexitatea în fata utilizatorului. Ar trebui să fie o mutare radicală în felul în care ne imaginăm şi dezvoltăm sisteme de calcul în ziua de azi. Acest lucru necesită mai mult decât modificarea unor sisteme vechi – calculul autonom cere un domeniu de studiu complet nou.
În contextul prezentat, scenariul ideal este unul unde defectele, noi caracteristici ale mediului, cerinţe de securitate nesatisfăcute şi schimbări în implementarea serviciilor sunt detectate dinamic şi automat, şi, dacă este necesar, “reparate”, de către sistemele însele, fără a fi necesara intervenţia umană externă, imediat când aceste probleme apar. Sistemele digitale capabile să detecteze şi, eventual, să corecteze propriile lor greşeli în funcţionare se numesc sisteme cu auto-întreţinere.
Definiţia sistemelor cu auto-întreţinere vine din contextul calculului autonom, adică a sistemelor de calcul care sunt în stare să se gestioneze pe ele însele şi primesc obiective de nivel înalt de la administratori. Ideea calculului autonom a fost introdus de vicepreşedintele de cercetare senior de la IBM, Paul Horn, în prezentarea sa la „National Academy of Engineers” de la universitatea Harvard în Martie 2001, ca singura cale eficientă de a trata obstacolul major în dezvoltarea continuă a industriei IT, anume complexitatea software. Momentan, IBM şi alţi producători sponsorizează cercetarea pentru identificarea, găsirea şi determinarea cauzei de bază a defectărilor în sistemele de calcul complexe, scopul final fiind construirea unor sisteme care pot trata aceste probleme în mod automat. Totuşi, în ciuda utilităţii sperate, cercetarea sistemelor cu auto-întreţinere este încă la începuturi şi investiţiile din industrie sunt limitate, pentru ca inovaţiile propriu-zise vor apare doar în timp şi cu riscuri majore.
Azi, sistemele cu auto-întreţinere sunt populare şi eficiente doar în proiectarea şi producţia de dispozitive integrate hardware (cum sunt plăcile cu memorii), dar cercetarea aplicaţiilor lor în domeniul software şi sisteme eterogene este încă în stadiu preliminar. Diferenţa majoră dintre un dispozitiv cu auto-întreţinere şi o societate digitală cu auto-întreţinere este posibilitatea folosirii cunoştinţelor şi experienţei tuturor membrilor societăţii digitale pentru rezolvarea problemelor critice şi complexe. Într-o societate digitală cu auto-întreţinere, un dispozitiv defect poate fi reparat cu ajutorul cunoştinţelor celorlalţi indivizi, chiar dacă nu a fost proiectat iniţial pentru a trata problema detectată. De exemplu, societatea digitală poate avea abilitatea de a partaja o baza de cunoştinţe pentru rezolvarea problemelor pe care dispozitivele individuale nu le-ar putea rezolva.
Până acum, experimentele de început în domeniul sistemelor cu auto-întreţinere au explorat conceptual de auto-întreţinere din diferite puncte de vedere, uneori fără a observa legăturile posibile. Câteodată, studiile s-au focalizat asupra asigurării unor cerinţe şi performante de sistem specifice, sau la folosirea unei strategii particulare de reparare, de exemplu reconfigurarea arhitecturii, sau la monitorizarea şi controlarea unei caracteristici de sistem, de exemplu conectivitate instabilă în reţele fără fir. Această viziune fragmentată a problemelor se reflectă şi în terminologia diferită:
- Sistemele auto-adapive (Self-adapting) subliniază abilitatea sistemului de a-şi adapta automat comportamentul ca răspuns la schimbări în mediul de funcţionare. Sistemele auto-adaptive de obicei lucrează cu cerinţe non-funcţionale, ca disponibilitatea şi perfomanţa. De exemplu, în medii în care încărcarea sistemului se schimbă dinamic, cu schimbări majore, un sistem auto-adaptiv îşi poate modifica comportamentul ca să asigure calitatea aşteptată a serviciului.
- Sistemele auto-optimizatoare (Self-optimizing) se bazează pe capacitatea de optimizare a resurselor disponibile într-un mediu, pentru unele obiective, de regulă non-funcţionale. Un exemplu este capacitatea de alocare automată a procesoarelor disponibile pentru optimizarea performanţelor sistemului.
- Sistemele auto-configuratoare (Self-configuring) implementează strategii specifice de rezolvare a problemelor, bazându-se pe abilitatea de a-şi reconfigura arhitectura (adică relaţiile dintre componentele sistemului) pentru a asigura proprietăţi de nivel înalt, definite la nivel arhitectural. Un sistem cu auto-configurare poate, de exemplu, descărca şi instala automat componente noi sau scoate componente existente în scopul rezolvării unor probleme la instalare, integrare şi funcţionare ale sistemului.
- Sistemele auto-reparatoare (Self-repairing) pot detecta si corecta defecte funcţionale. De exemplu, ele pot detecta folosirea incorectă a memoriei şi pot asista la repararea acestor probleme în timpul funcţionării.
- Sisteme auto-protectoare (Self-protecting) sunt axate pe detectarea şi soluţionarea automată a problemelor de securitate. În această categorie intră sistemele de detecţie automată a intruziunilor, chiar dacă strategiile automate de rezolvare (altele, decât cele de detecţie) sunt rare în sisteme moderne de detecţie a intruziunilor.
Într-o viziune mai largă a conceptului de auto-întreţinere, diferite auto-facilităţi identifică mecanisme complementare ce pot coexista în aceleaşi sisteme pentru adresarea problemelor diferite. De exemplu, un sistem software poate trata cerinţe de performanţă cu mecanisme de auto-adaptare, proprietăţi arhitecturale cu o arhitectură auto-configuratoare, conectivitate instabilă cu management auto-reparator a stabilităţii, problemele de securitate cu capacităţi de auto-protecţie şi aşa mai departe.
Societăţi cu auto-întreţinere prin agenţi mobili: Agenţii mobili sunt programe software care pot fi mutate de pe un sistem pe altul, pentru execuţie într-un mediu la distantă. Când un agent mobil se mişcă, ia cu el propriul cod executabil, dar şi datele proprii. Ajungând la mediul de la distanţă, un agent mobil se poate prezenta, şi dacă este acceptat, poate obţine acces la hardware local, servicii şi date. Planificăm să folosim agenţi mobili pentru a controla dinamic calitatea serviciilor, dependabilitatea şi securitatea în societăţi de sisteme digitale. Vom analiza un scenariu în care agenţi mobili răspund de aplicarea cerinţelor, constrângerilor, standardelor, configuraţiilor şi procedurilor, specifice unei societăţi digitale anume, dar pot fi necunoscute pentru unii indivizi care participă la sistem. De exemplu, dacă o noua versiune a unui serviciu este instalat la locaţia unui ofertant de servicii, sistemul poate trimite un agent mobil ca să execute teste specifice pe loc, cu scopul validării conformanţei noii implementări cu cerinţele sistemului. Similar, un agent mobil cu auto-întreţinere poate instala un modul adiţional în indivizii unui sistem pentru creşterea nivelurilor lor de interoperabilitate şi securitate. Mai în general, plănuim utilizarea agenţilor mobili pentru asigurarea posibilităţii observării comportamentului sistemului, evaluarea constrângerilor impuse de societate şi aplicarea de corecturi dedicate, dacă este necesar, cu minim de efort. Agenţii mobili pot fi şi colectori de date, transmiţând informaţii despre condiţii de defect şi proceduri de reparare, care pot fi foarte folositoare în stabilirea unor facilităţi noi de auto-întreţinere şi care vor permite stabilirea unei baze de cunoştinţe în vederea deciziilor de auto-întreţinere în societate.
Folosirea tehnologiei cu agenţi mobili ca infrastructura de bază a mecanismelor de auto-întreţinere este o nouă alegere care poate însemna o inovaţie tehnologică şi o contribuţie ştiinţifică relevantă la cunoaşterea şi înţelegerea în domeniu. Pe parcursul proiectului, tehnologia cu agenţi mobili va fi integrată cu alte tehnici de verificare: analiza în timpul funcţionării, metode tolerante la defect, tehnici de înregistrare a testului, suport pentru auto-testarea componentelor şi arhitecturi reconfigurabile. Ne aşteptăm ca această integrare să permită infrastructuri cu auto-întreţinere mai puternice.
Obţinerea auto-întreţinerii prin mobilitate hardware: Folosirea logicii ne-specializate, a cărei funcţie poate fi modificată în timpul execuţiei pentru a înlocui o componentă hardware defectă sau pentru implementarea unei noi componente Built-In Self-Test, este foarte atractivă. Mai mult, conceptul de Mobilitate Hardware este legat de conceptul Agentului Mobil şi al Calculului Reparativ într-o formă în care configuraţiile hardware necesare nu trebuie să fie stocate pe sistemul destinaţie, ci pot fi descărcate la cerere. Mobilitatea hardware nu a mai fost aplicată la sisteme cu auto-întreţinere, unde credem că are şansa de a deveni o inovaţie semnificativă.
Obţinerea unei societăţi cu auto-întreţinere prin arhitecturi software reconfigurabile: recent, mai mulţi cercetători din comunitatea arhitecturilor software au început promovarea posibilităţii obţinerii capacităţii de auto-întreţinere cu ajutorul arhitecturilor reconfigurabile, adică a arhitecturilor software şi stilurilor arhitecturale care oferă nativ capacităţi de resetare dinamică a coordinării şi interacţiunii dintre componente, având ca scop asigurarea unor proprietăţi arhitecturale. Exemplele includ abilitatea de adăugare a unor servere redundante, modificarea lăţimii de bandă alocată unei conexiuni, adăugarea şi scoaterea componentelor, modificarea legăturilor dintre componente şi aşa mai departe. Folosind aceste mecanisme şi capabilităţi, administratorii pot folosi tactici de reconfigurare, care sunt aplicate automat când se detectează schimbarea unei proprietăţi.
Studiile curente arată ca aceste soluţii pot funcţiona bine pentru asigurarea unor proprietăţi non-funcţionale, cum ar fi disponibilitatea serviciilor şi performanţele. Totuşi, aplicabilitatea şi utilitatea arhitecturilor reconfigurabile în societăţi digitale cu auto-întreţinere este îndoielnică şi este necesară mai multă analiză.
Investigarea rolului aserţiilor adaptive pentru descoperirea problemelor neprevăzute: aserţiile şi verificările din timpul funcţionării au fost studiate exhaustiv în ingineria software pentru identificarea deviaţiilor de la comportamentele aşteptate ale sistemului şi a anomaliilor în semnalele de ieşire. Din păcate, aserţiile clasice sunt definite static în momentul dezvoltării şi nu pot captura schimbările neprevăzute şi evoluţiile in mediul de execuţie. Aşadar, ele nu se adaptează uşor la aplicaţii autonomice.
O societate de sisteme digitale poate avea miliarde de utilizatori potenţiali, sute de milioane de dispozitive conectate ce rulează aplicaţii comerciale, sute de miliarde de mesaje online şi tranzacţii. Ele vor face posibil mCommerce, vor susţine oferirea multor servicii diferite, vor întări aplicaţiile mari şi vor muta cantităţi imense de date. Pentru a face aceste aplicaţii viabile, de încredere şi sigure este obligatorie realizarea acestor predicţii şi permiterea companiilor româneşti şi europene să obţină o parte mare din această piaţă.
Cunoştinţele despre sistemele cu auto-întreţinere este încă la începuturi în comunitatea internaţională de cercetare, şi este necesară multa cercetare de bază şi exemple funcţionale pentru a face aceste idei promiţătoare viabile pentru industrie. Cercetarea industrială în acest domeniu atestă interesul în creştere în domeniu, dar investirea în această tehnologie presupune mari riscuri, în ciuda profitului promiţător pe termen lung.
Astăzi, sistemele digitale se folosesc pretutindeni. Tendinţa de a produce medii digitale este în creştere, şi este foarte probabil că în viitor, vom fi înconjuraţi de multe dispozitive eterogene, de la sisteme domestice la aplicaţii complexe ca aplicaţii de industria automobilelor, transport şi sisteme de control medical, care comunică între ele prin interfeţe distribuite şi fără fir. Vom vedea o nouă societate de sisteme digitale „trăind şi evoluând” în jurul şi în societatea noastră [13]. Indivizii acestei noi societăţi vor fi sisteme eterogene digitale şi omniprezente ce vor oferi productivitate şi flexibilitate ridicată. Infrastructura de comunicaţii a acestei societăţi se va baza aproape în întregime pe conexiuni fără fir. Citându‑l pe Paul Saffo, directorul Institutului pentru Viitor („Institute for the Future”): „În Era Comunicaţiilor, dispozitivele fără fir vor interacţiona cu mediul exterior şi nu vor mai fi limitate la Departamentul Informatic. Pe când metafora comunicaţiei erau telefoanele – adică, oameni vorbind cu oameni – metafora viitorului un dispozitiv prin care maşinile vorbesc cu alte maşini în numele oamenilor. Această dezvoltare va elibera oamenii pentru lucrul cu media, în timp ce maşinile se ocupă de informaţie.” Noi preconizăm că în 10‑20 ani complexitatea sistemelor de acest tip va creşte la dimensiuni inimaginabile: cum gestionăm peste de un miliard de oameni care‑şi folosesc telefoanele mobile, agendele electronice şi alte dispozitive inteligente cu fir şi fără fir, comunicând între ei şi interacţionând cu alte dispozitive ca terminale POS, sisteme de mesagerie, automobile, terminale GPS, datele firmei şi Internetul? În viziunea multor companii importante americane şi europene (ca IBM, Tryllian şi Warp 9), rezolvarea acestei probleme este următoarea mare provocare pentru industria TI şi cercetare. Totuşi, infrastructurile folosite astăzi ţin cu greu pasul cu astfel de inovaţii tehnologice, şi este dificil de crezut că soluţiile de azi vor putea fi scalate şi adaptate la sisteme complexe, distribuite şi interactive. În particular, complexitatea ridicată va aduce multe aspecte noi care pot afecta adânc calitatea şi funcţionalitatea sistemului, şi nu vor fi tratate prin tehnici tradiţionale de proiectare software:
Defecte tranzitorii [14,15]: În societatea sistemelor digitale, o defectare poate avea multe alte cauze noi, altele decât imprecizia din timpul dezvoltării. Defecte noi pot apărea din interacţiuni neaşteptate dintre dispozitive şi aplicaţii dezvoltate independent, stres imprevizibil şi interferenţe cu mediul, sau îmbătrânirea hardware‑ului (de exemplu, ruperi şi interferenţe de circuite, cauzând defecte de memorie şi procesor). Vorbim despre aceste defecte ca defecte tranzitorii, deoarece ele sunt dificil de reprodus în testare. Astfel, este rezonabil să presupunem că în viitorul apropiat, procentul defectelor detectate prin tehnici tradiţionale de verificare şi validare, ca, de exemplu, testarea la sfârşitul producţiei, nu vor fi suficiente pentru garantarea nivelului cerut de calitate, disponibilitate, fiabilitate şi siguranţă în funcţionare. Pe lângă acestea, soluţionarea unui defect tranzitoriu (detectat în timpul funcţionării) prin intervenţie manuală este impracticabilă în societatea sistemelor digitale, din mai multe motive, incluzând costurile enorme legate de reparaţiile post‑producţie, flexibilitatea inacceptabilă a metodelor opreşte‑repară‑reconfigurează‑reporneşte, şi imposibilitatea tehnicilor de detecţie tradiţionale de a fi scalate la complexitatea mare a sistemelor destinaţie.
Situaţii de lucru imprevizibile: Tehnologiile bazate pe componente şi orientate pe servicii sunt văzute, de obicei, ca cea mai bună soluţie pentru aplicaţii cu complexitate crescândă, direcţie demonstrată şi de disponibilitatea multor componente şi servicii de tip COTS – Commercial Off The Shelf – comerciale, de pe raft. Aceste tehnologii contribuie la sporirea problemei, ridicând întrebări noi şi dificile pentru testare şi analiză. Tehnicile de testare şi analiză de regulă presupun o cunoaştere completă a sistemului sub test, ca şi a cerinţelor şi mediului de execuţie. Din păcate, această situaţie nu este valabilă în societatea de sisteme digitale. De cele mai multe ori, componentele şi serviciile sunt proiectate şi dezvoltate independent, la producător, apoi sunt achiziţionate, montate şi folosite în aplicaţii cu necesităţi, scopuri şi proprietari diferiţi. Producătorii nu pot identifica cerinţele tuturor situaţiilor de utilizare, astfel că testarea izolată a componentelor şi a serviciilor, de către producători, în general nu este suficientă. Este probabilă apariţia unor defecte noi de fiecare dată când o componentă este utilizată într‑un context neprevăzut. Testarea integrării în mediul de folosire poate detecta o parte din defectele ce pot apărea, dar eficienţa tehnicilor tradiţionale este limitată de indisponibilitatea codului sursă, a specificaţiilor funcţionale şi non‑funcţionale şi a cunoaşterii detaliate a deciziilor interne de proiectare, caracteristici comune componentelor şi serviciilor COTS. În final, chiar dacă un defect a unei componente este diagnosticat cu succes, procesul de reparare presupune colaborarea cu producătorul componentei, ceea ce este dificil, dacă nu chiar imposibil de realizat.
Probleme şi pericole de securitate: Securitatea va fi o temă fierbinte în societatea sistemelor digitale. Componentele şi serviciile care „nu sunt de încredere”, adică acelea care nu sunt proiectate din punct de vedere a securităţii (dar pot interacţiona cu şi în societate), pun în pericol funcţionarea corectă a întregului sistem. Totuşi, dată fiind prezenţa dispozitivelor eterogene (de regulă mobile), ale căror hardware şi software poate evolua independent unul de celălalt, cerinţele de securitate sunt dificil de definit apriori pentru toate dispozitivele şi aplicaţiile. Probleme şi pericole de securitate neaşteptate pot apărea de fiecare dată sunt stabilite noi interacţiuni în timpul funcţionării, ducând la necesitatea impunerii şi verificării dinamice a securităţii de către societatea în sine.
Probleme de interoperabilitate: În societatea sistemelor digitale, dispozitivele interacţionează folosind serviciile unele altora, câteodată descoperind dinamic existenţa şi disponibilitatea serviciilor dorite. Totuşi, dată fiind independenţa completă dintre multe dispozitive, în general nu există control asupra implementării propriu‑zise a serviciilor folosite. De exemplu, un ofertant de servicii poate decide introducerea unei noi versiuni a unuia din serviciile sale, independent de utilizatorii serviciului. Uneori, utilizatorii pot fi chiar inconştienţi de faptul că au început să folosească o nouă versiune a serviciului. n alte cazuri, serviciile disponibile (şi detectabile dinamic) pentru un scop anume pot avea implementări diferite în spatele interfeţei identice. Capacitatea de a verifica şi evalua dinamic şi a garanta interoperabilitatea cu servicii care pot avea implementări „instabile” devine o problemă proeminentă în societatea sistemelor digitale [16]. În principiu, ofertanţii de servicii trebuie să aibă capacitatea de a modifica, introduce, retrage, reintroduce şi oprirea serviciilor lor, fără periclitarea funcţionalitatea întregului sistem sau a dispozitivelor care participă la el.
Dat fiind acest scenariu, este destul de greu să credem că soluţiile de azi vor fi scalabile şi adaptabile la sisteme complexe, distribuite şi interactive de viitor.
Pe de altă parte, sunt două tehnologii care ies în evidenţă în sprijinirea acestei paradigme: Agenţi de Date Mobili („Mobile Data Agents”) pentru infrastructura de comunicaţii şi Sisteme Reconfigurabile („Reconfigurable Systems”) pentru implementarea unor „indivizi” configurabili, adaptivi, reparabili şi cu performanţe ridicate [17,18].
Agenţii de Date Mobili [19,20] sunt o tehnologie gata disponibilă şi relativ viabilă. Ei sunt agenţi software care pot fi deplasaţi de la un sistem la altul şi pot fi transportaţi pe un dispozitiv la distanţă pentru execuţie. Ajungând la calculatorul de la distanţă, Agenţii Mobili se prezintă şi obţin acces la hardware‑ul local, servicii şi date. Când un Agent se deplasează, ia cu el codul program executabil, dar şi datele sale. Agenţii de Date Mobili sunt mici, siguri, dinamici şi, în general, independenţi de hardware.
Sistemele Reconfigurabile au capacitatea de reprogramare a circuitelor hardware în timpul funcţionării. De exemplu, este posibilă schimbarea din mers a protocolului de comunicaţie a unei interfeţe de ieşire, sau programarea logicii reconfigurabile să implementeze un bloc de procesare specific unui algoritm de procesare imagini. În general, sistemele reconfigurabile sunt folosite la obţinerea celei mai bune performanţe cu utilizarea la maxim a hardware‑ului. Circuitele sunt încărcate şi descărcate dinamic din hardware în timpul funcţionării sistemului. Suprafaţa folosită de astfel de sisteme este deci mai redusă faţă de un sistem static, datorită descărcării circuitelor neutilizate. Sistemele reconfigurabile sunt, de regulă, proiectate cu un amestec de logică fixă şi cipuri FPGA. Sistemele Reconfigurabile bazate pe tehnologie FPGA vor domina proiectarea sistemelor înglobate în aproximativ zece ani. Ele vor transforma telefoanele celulare, camerele foto şi video, PLD‑urile simple, microcontrolerele şi memoriile în variante revoluţionare ale predecesorilor lor.
3. Sisteme multiagent
3.1. Introducere
Dezvoltarea exponenţială a informaticii şi microelecronicii în ultima perioadă, creşterea continuă a gradului de integrare a sistemelor, miniaturizarea şi realizarea unor sisteme digitale tot mai complexe şi integrate la o scară din ce în ce mai largă, precum şi pătrunderea electronicii digitale în cadrul unor sisteme răspândite pe o arie geografică largă, formate dintr-un număr mare de subsisteme eterogene, toate alăturate nivelului din ce în ce mai înalt de cerinţe de calitate şi fiabilitate ale tuturor dispozitivelor amintite, şi standardelor din ce în ce mai stricte din domeniu, dau naştere necesităţii unor noi metode de testare.
În cadrul sistemelor eterogene distribuite şi răspândite pe o arie largă, cum sunt cele pe care le-am amintit, testarea clasică, locală, nu poate oferi rezultate cu o vedere de ansamblu asupra sistemului, datorită numărului extrem de mare de subsisteme elementare şi a naturii eterogene a acestora. Se impune aşadar testarea la distanţă, cu centralizarea rezultatelor. Această soluţie este aplicabilă, însă aduce cu ea noi complicaţii: resursele de comunicare ale sistemului sunt foarte încărcate cu traficul de date legate de testare, centralizarea datelor este un proces dificil şi care la rândul lui consumă resurse, şi proiectarea modulelor software sau hardware de testare este dificilă datorită activităţilor diverse şi complexe pe care acestea trebuie să le desfăşoare.
O soluţie descentralizată, distribuită, pe de altă parte, este mult mai uşor de proiectat, implementat, întreţinut şi utilizat [21]. Abordarea descentralizată opreşte problemele la nivelul la care ele sunt soluţionabile, reducând aşadar necesităţile de comunicaţie. Flexibilitatea procesului de testare şi scalabilitatea sistemului care efectuează testarea sunt de asemenea avantaje care nu pot fi ignorate.
În tehnologia software îşi face loc din ce în ce mai mult în ultima vreme un nou concept: agent inteligent [22]. Acesta este un program independent, mobil, care este capabil de a funcţiona înspre îndeplinirea unor scopuri de o manieră flexibilă, şi într-un mediu în continuă schimbare. El face aceasta prin urmărirea stării lumii înconjurătoare şi învăţarea din experienţă. Prin gruparea agenţilor în societăţi în cadrul cărora ei comunică, învaţă unii de la alţii, se alătură pentru a rezolva probleme care le depăşesc capabilităţile individuale, se formează ceea ce se cheamă sisteme multiagent. Acestea sunt remarcabile prin capacitatea globală de soluţionare a problemelor şi prin nivelul ridicat de adaptabilitate la un mediu în schimbare.
Mulţi oameni de ştiinţă şi cercetători afirmă că agenţii inteligenţi reprezintă un concept important in sistemul de operare al viitorului. Sistemele de calcul, precum şi reţelele de calculatoare sunt în continuă creştere şi complexitate. În contrast cu acest trend, costul scăzut şi capacitatea mărită a echipamentelor de calcul, precum şi extinderea neaşteptată a reţelelor, un exemplu elocvent îl putem da ca fiind Internetul, a făcut posibil ca aceste resurse să fie folosite individual cu o pregătire scăzută, dacă se poate spune, pentru uzul personal. Apar o serie largă de probleme ca de exemplu ştergerea accidentală a fişierelor, incapacitatea de a configura un sistem de calcul întâmpinată de incompatibilitatea dintre aplicaţii şi sistem, dificultăţile în efectuarea service-ului sistemului şi rezolvarea acestor probleme cu ajutorului celei mai moderne reţele de comunicaţie şi anume Internetul.
Agenţii inteligenţi sunt dezvoltaţi întocmai pentru a veni in sprijinul soluţionării acestor probleme. Cei mai de seamă producători, incluzând Microsoft, Apple, IBM şi SUN Microsystems dezvoltă soluţii pentru utilizarea produselor lor într-o lume diversificată, prin urmare sunt multe mărci care în momentul de faţă se ocupă cu studiul si dezvoltarea unor soluţii noi de agenţi inteligenţi.
3.2. Ce sunt agenţii?
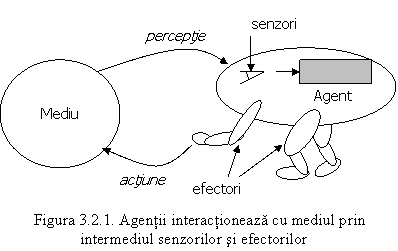
Un agent este orice entitate care poate fi văzută ca percepând mediul prin intermediul unor senzori şi acţionând asupra acestuia prin intermediul unor efectori. Un agent uman are ochi, urechi şi alţi analizatori pe post de senzori, şi mâini, picioare, gură şi alte părţi ale corpului pe post de efectori. Un agent robotizat, spre exemplu, foloseşte camere şi detectori cu infraroşu pe post de senzori, şi diverse motoare pe post de efectori. Un agent software îşi reprezintă acţiunile şi percepţiile ca şiruri codificate de biţi. Un agent generic este schematizat în figura 3.2.1.
O definiţie care pare a fi cuprinzătoare a fost dată de J. Ferber şi care are următorul enunţ: „Se numeşte agent inteligent o entitate reală sau abstractă care este capabilă de a acţiona asupra ei înşişi si asupra mediului său, care dispune de o reprezentare parţială a acestui mediu, care într-un mediu multi-agent poate comunica cu alţi agenţi şi al cărui comportament este consecinţa observaţiilor sale, cunoştinţelor sale şi interacţiunilor cu alţi agenţi”.
 Un agent
raţional este un agent care face întotdeauna lucrul care trebuie
făcut. În mod evident, aceasta este mai bine decât a face lucrul incorect,
dar ce înseamnă lucrul corect? Într-o primă aproximare, vom spune
că acţiunea corectă este cea care duce agentul înspre succesul
maxim. Rămâne de decis când şi cum se evaluează
succesul agentului.
Un agent
raţional este un agent care face întotdeauna lucrul care trebuie
făcut. În mod evident, aceasta este mai bine decât a face lucrul incorect,
dar ce înseamnă lucrul corect? Într-o primă aproximare, vom spune
că acţiunea corectă este cea care duce agentul înspre succesul
maxim. Rămâne de decis când şi cum se evaluează
succesul agentului.
Cum se determină succesul unui agent? Pentru aceasta există noţiunea de performanţă. Evident, nu există o măsură a performanţei validă pentru toţi agenţii. Putem, desigur, întreba agentul cât este de mulţumit cu performanţele sale, dar unii agenţi nu vor putea răspunde, iar alţii se vor supraevalua. Este aşadar nevoie de un criteriu obiectiv de evaluare a performanţei, stabilit de către o autoritate externă.
Când se efectuează măsurarea performanţei este de asemenea important. Dacă performanţa se măsoară la un timp scurt după ce agentul îşi începe munca, pot fi favorizaţi agenţii care încep în forţă şi apoi pot să încetinească sau să se oprească din muncă, faţă de cei care lucrează mai încet, dar constant. În acest caz este deci nevoie de evaluarea performanţei la intervale mai mari de timp.
Trebuie făcută distincţia între raţionalitate şi omniscienţă. Un agent omniscient va cunoaşte întotdeauna efectele acţiunilor sale, şi aşadar va face întotdeauna lucrul corect. Dar omniscienţa este imposibilă în realitate. Raţionalitatea se ocupă mai degrabă de succesul aşteptat având în vedere ceea ce s-a perceput. Cu alte cuvinte, un agent nu poate fi învinuit de faptul că nu ţine cont de ceva pe care nu îl poate percepe, sau că nu efectuează acţiuni pe care efectorii lui nu i le permit.
Definiţia unui agent raţional ideal rezultă deci ca fiind următoarea: pentru orice secvenţă de percepţii, un agent raţional ideal trebuie să efectueze acţiunea de la care se aşteaptă să îi maximizeze performanţele, pe baza datelor provenite din secvenţa de percepţii şi din cunoştinţele încorporate pe care agentul le are.
O noţiune importantă apare în această definiţie: “cunoştinţele încorporate” ale agentului. Dacă acţiunile agentului se bazează exclusiv pe cunoştinţele încorporate iniţial în el, astfel încât agentul nu are deloc nevoie să fie atent la percepţii, se spune că acelui agent îi lipseşte autonomia. Comportamentul agentului poate fi astfel proiectat încât să se bazeze atât pe experienţa sa cât şi pe cunoştinţele încorporate la construcţia agentului adaptat la mediul specific în care el acţionează. Un sistem este autonom în măsura în care comportamentul său este determinat de experienţă.
Nici impunerea unei complete autonomii a agentului nu va funcţiona. Când agentul nu are deloc sau are puţină experienţă, el va trebui să acţioneze aleator în lipsa oricărei îndrumări din partea proiectantului. Astfel, aşa cum evoluţia dotează animalele cu reflexe necondiţionate încorporate pentru a putea supravieţui destul timp cât să înveţe pentru ele însele, şi un agent autonom va trebui dotat, pe lângă abilitatea de a învăţa, şi cu un set de cunoştinţe iniţiale.
3.3. Structura agenţilor inteligenţi
Până acum expunerea a fost efecutată doar în termeni de comportament al agentului – ce face un agent ca răspuns la percepţiile primite. Vom intra mai departe în detalii asupra felului în care un agent este construit. Proiectarea unui agent înseamnă de fapt proiectarea programului agent: o funcţie care realizează transformarea între percepţiile şi acţiunile agentului. Presupunem că acest program rulează pe un tip oarecare de calculator, care va fi numit arhitectura agent. În mod obligatoriu, programul ales trebuie să fie unul pe care arhitectura îl va accepta şi rula.
Arhitectura poate fi un simplu calculator, sau poate include hardware specializat pentru sarcini specifice, spre exemplu procesarea de imagini video sau filtrarea intrărilor audio. Ea poate include şi un nivel software care oferă un anumit grad de separare între maşina de bază, efectivă, şi programul agent, spre a da posibilitatea programării acestuia din urmă la un nivel mai înalt. În general, arhitectura face percepţiile accesibile programului agent, rulează acest program, şi acţionează efectorii pe baza alegerilor de acţiune efectuate de program. Relaţia între agenţi, programele agent şi arhitecturile pe care acestea rulează poate fi rezumată în următoarea relaţie: agent = arhitectură + program
3.4. Tipuri de programe agent
Pentru a introduce principalele tipuri de programe agent, vom considera un exemplu. Fie acesta un şofer automat de taxi. Taxiul va trebui să ştie în fiecare moment în ce loc este, ce altceva se mai află pe şosea, şi cu ce viteză se deplasează (într-o viziune, evident, simplificată). Aceste informaţii pot fi obţinute de la camere de luat vederi controlabile, vitezometru, etc. Spre a putea controla vehiculul, va fi nevoie de un accelerometru. Va fi de asemenea nevoie de cunoaşterea stării motorului, şi astfel apare nevoia uzualului şir de senzori plasaţi la nivelul motorului şi sistemului electric.
Acţiunile disponibile şoferului automat de taxi vor fi mai mult sau mai puţin aceleaşi cu cele disponibile unui şofer uman: control asupra motorului prin intermediul acceleraţiei şi control asupra direcţiei şi frânelor. Va fi nevoie de un sistem de tip sintetizator de voce spre a putea comunica cu pasagerii şi eventual de un sistem adaptat comunicării cu alte vehicule.
Rămâne de decis cum se va implementa programul efectiv care va face transformarea din percepţii în acţiuni. Vom considera patru tipuri de programe, detaliate pe rând mai jos:
§ agenţi reflecşi simpli.
§ agenţi care urmăresc evoluţia lumii.
§ agenţi orientaţi pe scop.
§ agenţi bazaţi pe utilitate.
a) Agenţi reflecşi simpli
Varianta construcţiei unei tabele simple de transformare între percepţii şi acţiuni este imposibilă. Fluxul de intrare de la o cameră are el singur o rată de 50 de megaocteţi pe secundă (25 de cadre pe secundă, 1000 x 1000 pixeli cu 8 biţi de culoare şi 8 biţi de informaţie de intensitate). Aşadar, tabela de transformare pentru o oră are dimensiunea de 260x60x50M.
Cu toate acestea, porţiuni din tabel pot fi sintetizate dacă se observă asociaţii comune şi frecvente intrare-ieşire. Astfel, dacă stopurile maşinii din faţă se aprind, asta înseamnă că ea frânează şi aşadar va încetini. Spre a evita impactul, şi şoferul automat de taxi va trebui să frâneze. Aşadar, dacă pe baza unei procesări a informaţiei vizuale de intrare se deduce că “maşina din faţă frânează”, atunci trebuie efectuată acţiunea “iniţiază frânarea”, pe baza unei conexiuni în programul agent
b) Agenţi care urmăresc evoluţia lumii
Să considerăm următoarea situaţie. Din timp în timp, şoferul de taxi priveşte în oglinda retrovizoare spre a determina dacă, unde şi cu ce viteze se deplasează autovehicule în spatele vehiculului propriu. Când şoferul nu se uită în oglindă, vehiculele sunt invizibile, adică starea lor nu îi este direct accesibilă. Cu toate acestea, dacă spre exemplu şoferul se decide să schimbe banda, el trebuie să ştie dacă vehiculele sunt acolo sau nu.
Un agent reflex nu poate să facă acest lucru. Este nevoie de menţinerea stării lumii, ori pentru aceasta este nevoie de două tipuri de cunoştinţe: cum evoluează lumea în lipsa acţiunilor agentului – spre exemplu, că o maşină angajată în depăşire va fi în general tot mai aproape în spate pe măsură ce trece timpul; şi cum influenţează acţiunile efectuate de agent lumea.
c) Agenţi orientaţi pe scop
Cunoaşterea stării lumii nu este întotdeauna de ajuns spre a decide care este lucrul de făcut în momentul următor. Spre exemplu, la o intersecţie, taxiul poate vira stânga, dreapta, sau poate să îşi menţină direcţia de mers. Decizia corectă depinde de punctul în care taxiul trebuie să ajungă. Cu alte cuvinte, agentul trebuie să cunoască, pe lângă descrierea stării curente a lumii, şi informaţii despre scopurile agentului – spre exemplu, ajungerea la destinaţia pasagerului. Programul agent poate combina aceste informaţii cu rezultatele acţiunilor disponibile (aceleaşi care sunt folosite şi înainte) spre a alege acţiunile care îi îndeplinesc scopurile. Această alegere poate fi, după caz, mai simplă, sau mai complicată.
d) Agenţi bazaţi pe utilitate
Scopurile nu sunt suficiente spre a genera un comportament calitativ superior. Spre exemplu, există multe secvenţe de acţiuni care determină taxiul să ajungă la destinaţia dorită, dar unele sunt mai rapide, mai sigure, mai de încredere sau mai ieftine decât altele. Scopurile dau doar o distincţie grosieră între stări “bune” şi “rele” ale lumii. În cele mai multe situaţii însă, o distincţie mai fină trebuie să se facă între diverse stări sau succesiuni de acţiuni. Pentru aceasta se introduce noţiunea de utilitate. Utilitatea este aşadar o transformare între o stare şi un nivel asociat de “mulţumire” al agentului.
3.5. Mediul agent
Lucrul esenţial care trebuie observat în legătură cu mediile agent şi la care ne vom opri este clasificarea acestora. Există mai multe criterii de clasificare, tipurile de medii fiind sintetizate în lista dată mai jos:
§ Accesibil / inaccesibil. Dacă aparatul senzorial al unui agent îi oferă acces la starea completă a mediului, vom spune că mediul este accesibil acelui agent. Un mediu este efectiv accesibil dacă senzorii detectează toate aspectele relevante în alegerea acţiunii de efectuat. Un mediu accesibil este convenabil deoarece agentul nu trebuie să menţină intern informaţii despre starea lumii.
§ Determinist / nedeterminist. Dacă starea viitoare a mediului este complet determinată de starea curentă şi de acţiunile agentului, atunci mediul este determinist. În principiu, un agent nu trebuie să se ocupe de incertitudine într-un mediu accesibil şi determinist. De notat că un mediu inaccesibil, chiar dacă este nedeterminist, îi va apărea agentului nedeterminist. Astfel, determinismul este mai bine înţeles dacă este privit din punctul de vedere al agentului.
§ Episodic / neepisodic. Într-un mediu episodic, experienţa agentului este divizată în “episoade”. Fiecare episod constă din agentul care raţionează şi apoi acţionează. Calitatea acţiunii depinde doar de episodul în sine. Mediile episodice sunt mai simple, deoarece agentul nu trebuie să gândească înainte în timp.
§ Static / dinamic. Dacă mediul se poate schimba în timp ce agentul deliberează, el este dinamic pentru agent. Altfel, este static. Dacă mediul nu se schimbă în acest timp, dar se schimbă performanţa agentului, mediul se cheamă semidinamic.
§ Discret / continuu. Dacă există un număr clar definit, limitat, de percepţii şi acţiuni, mediul este discret. Şahul spre exemplu este un mediu discret, pe când şofatul unui taxi este continuu, locaţia şi viteza vehiculelor variind într-o gamă continuă de valori.
4. Componenţa unui agent inteligent
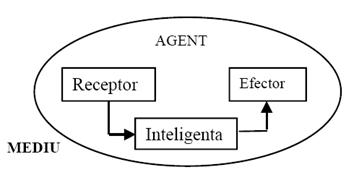
Figura. 4.1. Structura simplificată a unui agent inteligent
Un agent inteligent evoluează într-un mediu. El trebuie să fie în măsura să primească informaţii din acest mediu prin intermediul receptorilor şi de a actiona asupra mediului prin intermediului efectorilor, având un comportament stabilit, plecând de la observaţiile şi raţionamentul propriu. Existenţa modulelor de comunicare este esenţială, cu atât mai mult cu cât mediul este constituit din alti agenţi cu care agentul poate coopera pentru a-şi atinge obiectivul.
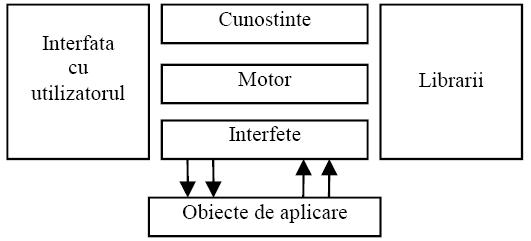
Figura. 4.2. Componentele unui agent inteligent
- Motorul este „ creierul agentului”.
- Cunoştintele reprezintă ceea ce agentul ştie, crede şi gândeşte. Cunoştintele pot fi bazate pe
aplicaţii existente cum ar fi, de exemplu, o bază de date sau un agent mesager. Cunoştintele sunt stocate in librării.
- Interfaţa cu alte aplicaţii, care poate fi, de exemplu, cu curierul electronic sau cu web-ul, determina domeniul de aplicare al unui agent.
- Interfaţa cu utilizatorul permite comunicarea între agent şi utilizator. Utilizatorul dă instrucţiuni agentului şi acesta din urmă trimite înapoi rezultatele sau datele despre informaţiile cerute. Aceasta interfaţă poate fi una grafică uzuală, dar se preconizează realizarea de interfeţe complexe care să permită utilizarea limbajului natural vorbit, care va permite utilizatorului o interacţiune prietenoasă cu agentul. O asemenea interfaţă va trebui sa conţină o unitate de recunoaştere a vorbirii, de sinteză vocală şi de întelegere a limbajului natural.
5. Caracteristicile agentului inteligent
Cercetarea asupra tehnologiilor agenţilor este relativ recentă şi este într-o perpetuă evoluţie, de aceea nu există o unanimitate de păreri în acest domeniu. Totuşi, se pot identifica câteva caracteristici pe care un agent trebuie să le îndeplinească pentru ca el sa poata fi numit agent inteligent.
5.1. Inteligenţa
Inteligenta este capacitatea de a rationa si de a invata. Datorita ei agentul accepta intrebarile utilizatorului si tot ea il conduce in activitatea pe care trebuie sa o desfasoare. In cazul unui grad de inteligenta minim, utilizatorul poate specifica preferintele sale, de exemplu sub forma de reguli, iar agentul este inzestrat cu un mecanism de rationament care actioneaza in raport cu aceste preferinte.
La un grad de inteligenţă mai elevat, agentul va trebui să înţeleagă ceea ce utilizatorul vrea şi să planifice mijloacele necesare atingerii scopului.
5.2. Interactivitatea
În figura 5.2. sunt arătate componentele mediului cu care un agent poate reacţiona: oamenii, hardware-ul, alti agenţi şi software-ul care nu este al agenţilor. Aceste interacţiuni au nivele diferite în funcţie de complexitatea componentelor.
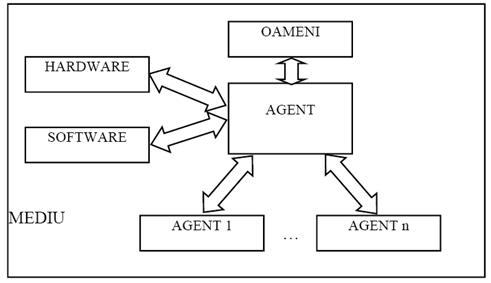
Figura 5.2. Interacţiunile agentului inteligent
a) Interacţiunea cu hardware-ul
Se realizează în general prin intermediul programului, acesta fiind necesar adesea pentru a controla caracteristicile fizice. Lumea fizică impune ca, pe lângă program, agentul să dispună de interfeţe de conectare a traductoarelor care îi furnizează informaţia din mediul fizic şi interfeţe de conectare a elementelor de acţionare asupra mediului fizic.
b) Interacţiunea cu software-ul
Agenţii trebuie sa poată colabora cu aplicaţii care au fost astfel concepute încât să pară ca o fiinţă umană participa la interacţiune.
c) Interacţiunea cu oamenii
Aceasta poate fi foarte complexa, in mod ideal oamenii trebuind sa aiba posibilitatea de a comunica cu agenţii in acelaşi mod cum o fac cu alti oameni. Tehnologia actuală nu permite standardizarea unei asemenea interacţiuni totale, dar permite o standardizare parţială a ceea ce agenţii primesc de la om. In acest context apar doua probleme principale si anume:
- cooperarea şi schimbul de informaţii cu oamenii;
- autentificarea utilizatorului.
d) Interacţiunea cu alţi agenţi
Agentul este capabil sa interacţioneze cu alţi agenţi, aşa cum comunica persoanele intre ele. Pentru a-si coordona activităţile doi agenţi trebuie sa negocieze pentru a ajunge la un acord acceptabil pentru ambele părţi. Avantajele rezultate din interacţiunea între agenţi diferiţi sunt:
- capacitatea de a rezolva problemele foarte complexe, care depăşesc resursele unui singur agent;
- cooperarea între agenţi cu sarcini şi roluri diferite;
- furnizarea de soluţii la problemele distribuite natural, cum ar fi de exemplu, gestionarea traficului aerian, naval etc;
- ameliorarea modularităţii, fiabilităţii şi flexibilităţii.
Pentru ca aceasta interacţiune să se realizeze, trebuie să existe un limbaj de comunicare între agenţi. Astfel de limbaje sunt în plina dezvoltare, dar se impune o standardizare pentru a putea realiza o comunicare între toţi agenţii.
5.3. Mobilitatea
Unii agenti pot fi ficşi, adica ei sunt rezidenti fie în calculatorul utilizatorului, fie pe server. Alţi agenţi pot fi mobili, putându-se deplasa prin reţea. Ei se pot deplasa din calculator în calculator, transportând pe durata execuţiei lor datele acumulate. Aceşti agenti se pot adresa altor agenţi pentru a li se face anumite servicii. Mobilitatea implică rezolvarea unor probleme de securitate, de protecţie a vieţii private şi a datelor confidenţiale. In consecinţă, va trebui să se faca apel la agenţi de securitate care să supravegheze activitatea agenţilor care se instalează pe un calculator. Pe termen lung trebuie să se ia neconditionat în calcul posibilitatea deplasării şi a comunicării între agenţi.
5.4. Alte caracteristici
Vom prezenta mai jos alte insusiri pe care poate sa le posede un agent. Acestea nu sunt
indispensabile pentru profilul agentului, dar ele permit caracterizarea unui agent particular.
a) Reactivitatea
Agentul trebuie sa faca fata modificarilor mediului, cum ar fi modificarea obiectivelor sau a resurselor disponibile.
b) Delegarea
Agentul este mandatat de catre utilizator pentru a indeplini o sarcina. In cazul comertului electronic un grad de delegare slab ar implica ca agentul va cauta oportunitatile interesante si le va propune utilizatorului. La un grad de delegare mai ridicat agentul efectueaza el insusi cumpararea. In acest caz exista riscul ca agentul sa efectueze o operatie necorespunzatoare, utilizatorul trebuind sa aiba un anumit grad de incredere.
c) Domeniul de aplicare
Domeniul de aplicare este important privit prin prisma riscului pe care-l comporta realizarea actiunii agentului. Astfel, daca este vorba de a tria corespondenta electronica, riscul pe care-l comporta o asemenea operatie este unul minor, dar când este vorba de a controla o centrala nucleara, trebuie reflectat de doua ori inainte de a incredinta o asemenea sarcina unui agent, pentru ca comportamentul sau nu este perfect previzibil.
d) Autonomia
Agentul poate efectua spontan anumite activitati, poate avea initiative. Ceea ce-l deosebeste de un program obisnuit este posedarea unui obiectiv, ceea ce-i permite sa fie autonom.
e) Personalizarea
Utilizatorul determina maniera in care agentul reactioneaza. In multe cazuri, agentul se adapteaza la utilizator.
f) Previziunea
Este necesar ca utilizatorul sa prevada ce fel de rezultate poate astepta de la agent.
g) Rentabilitatea
Trebuie ca avantajele obtinute de utilizator (timp câstigat, informatie furnizata, filtrarea informatiilor) sa fie superioare costului (bani cheltuiti, timp consumat etc.)
h) Comunicarea
Se stabileste o comunicare intre utilizator si agent pentru a determina activitatea agentului.
i) Degradarea progresivă
Daca apare o problema, de exemplu una de comunicare sau o activitate pe care agentul nu o poate efectua, acesta nu trebuie sa se blocheze complet, ci trebuie sa continue sa execute ceea ce poate, eventual prin alte mijloace.
j) Antropomorfismul
Anumite caracteristici umane pot fi utile. De exemplu, cunoasterea unui limbaj natural permite sa se specifice lucrurile ce trebuie efectuate fara a fi nevoie de a folosi un limbaj particular pentru a specifica regulile sau a cunoaste o interfata particulară a unui agent.
6. Arhitecturi posibile
6.1. Arhitectura reflexivă
Ideea agentului reflexiv bazat pe un rationament pur logic este foarte seducatoare. Pentru a se realiza un agent de un asemenea fel trebuie sa se rezolve cel putin două probleme importante:
- Problema traducerii. Cum sa se traduca lumea reala intr-o descriere simbolica, precisa si adecvata, astfel incât aceasta descriere sa fie utila
- Problema rationamentului. Cum sa se reprezinte intr-o maniera simbolica procesele si entitatea lumii reale si ce trebuie facut ca agentul sa rationeze folosind aceasta informatie intr-un timp acceptabil pentru care rezultatele sa fie utile.
6.2. Arhitectura reactivă
Pentru a evita problemele nerezolvate de catre inteligenta artificiala, unii cercetatori au trecut la dezvoltarea arhitecturii reactive, care nu contine modele simbolice ale lumii si nu utilizeaza rationamentul simbolic complex. Acest tip de arhitectura este, de exemplu, compusa dintr-un ansamblu de module de competenta autonome, insarcinate cu un anumit lucru si care poseda fiecare un anumit nivel de activare. Aceste nivele sunt conectate intre ele prin legaturi:
- cu predecesorul: pentru ca un lucru sa poata fi realizat, trebuie ca o conditie sa fie indeplinita. In acest caz fie exista o legatura a agentului cu predecesorul fie exista module care sa realizeze conditia.
- cu succesorul: daca un lucru a fost efectuat, aceasta poate permite ca alte lucruri sa fie efectuate.
- conflictuala: doua lucruri pot fi exclusive, efectuarea unuia dintre ele excluzând posibilitatea
ca celălalt sa poată fi realizat.
La acest tip de arhitectura activarea se propaga in retea, prezentând similaritati cu retelele neuronale. Deosebirea fundamentala intre ele consta în faptul ca un nod dintr-o reţea neuronală nu poate fi asimilat cu un modul de competenta al unui agent inteligent, deoarece acesta are o semnificaţie bine determinată.
6.3. Arhitectura hibridă
Arhitecturile hibride tind să reunească avantajele celor două tipuri prezentate anterior. O maniera simplă de a le combina este de a construi o structură compusă din două (sau mai multe) subsisteme, unul fiind reflexiv, iar celălalt reactiv.
7. Platforma multiagent
Societatea multiagent pentru testarea distribuită are anumite caracteristici care impun tipuri de funcţionalitate corespunzătoare platformei multiagent care suportă această societate. Astfel, pentru a forma o societate, capabilitatea de bază a agenţilor trebuie să fie comunicarea. De asemenea, pentru a face posibilă distribuţia agenţilor de testare în spaţiul reţelei distribuite în funcţie de variaţiile de sarcini de testare din diverse puncte ale acesteia, o altă capabilitate a acestora trebuie să fie mobilitatea. Vorbind despre comunicare, trebuie observat că un agent nu are de unde să “ştie” a priori cu ce agent să comunice pentru a rezolva un anumit tip de sarcină. Pentru a face posibilă publicarea diverselor tipuri de servicii pe care un agent este capabil să le execute, precum şi obţinerea de referinţe de către un agent interesat într-un anumit tip de serviciu înspre agenţii care îl furnizează, este nevoie de ceea ce se numeşte un sistem de management al societăţii de agenţi. De asemenea, la nivel de implementare, platforma trebuie să asigure un model de acţiune coerent, flexibil şi intuitiv pentru agenţi.
8. FIPA
Fundaţia pentru Agenţi Inteligenţi Fizici (FIPA) [23] a fost formată în anul 1996 cu scopul de a produce standarde software pentru agenţi eterogeni şi sisteme eterogene bazate pe agenţi, aflate în interacţiune. Pentru producerea acestor standarde, FIPA solicită ideile şi colaborarea membrilor săi, precum şi în general cercetătorilor ce activează în domeniu. Rezultatele se materializează într-un set de specificaţii ce pot fi folosite în dobândirea inter-operabilităţii între sisteme agent dezvoltate de diverse companii şi organizaţii.
FIPA este organizată şi structurată în jurul a două grupuri – unul care se ocupă de producerea şi dezvoltarea standardelor, şi un al doilea care este implicat în mecanismul-suport al FIPA. Munca de standardizare este efectuată la întâlniri cvadrianuale, în strânsă legătură cu alte organisme de standardizare cum ar fi OMG[1].
Misiunea declarată a FIPA este aceea de a facilita execuţia cooperantă a activităţilor agenţilor şi sistemelor agent rulând sub platforme agent multiple şi eterogene. Accentul se pune pe utilitatea comercială şi industrială practică a sistemelor agent; cu toate acestea, nu sunt lăsaţi deoparte nici agenţii cognitivi sau inteligenţi. Mesajul de esenţă al FIPA este că, printr-o combinaţie de acte de comunicare, logică şi ontologii publice, pot fi oferite modalităţi standard de interpretare a comunicării inter-agent într-un fel care respectă semnificaţia dorită a comunicării.
Spre a îndeplini aceste deziderate, FIPA a adoptat şi lucrează la specificaţii ce acoperă arii începând cu arhitecturi ale sistemelor agent ce suportă comunicarea inter-agent şi terminând cu limbaje de comunicare şi limbaje de conţinut pentru exprimarea respectivelor mesaje şi protocoale de interacţiune, ce extind raza acţiunii de comunicare de la mesaje simple la tranzacţii complexe şi complete. În viitor, standardele intenţionează să trateze chiar relaţii pe termen lung între agenţi.
8.1. Acte de comunicaţie
8.1.1. Structură
Un mesaj FIPA ACL constă dintr-un set de unul sau mai mulţi parametri de mesaj. Numărul şi felul parametrilor necesari pentru comunicaţia efectivă a agenţilor variază în funcţie de situaţie; singurul parametru obligatoriu este performativul (performative), dar mesajele vor conţine în cele mai multe cazuri adresele emiţătorului, receptorului şi o parte de conţinut (sender, receiver, content).
Dacă un agent nu recunoaşte sau nu poate procesa una sau mai multe dintre valorile parametrilor mesajului, el va replica cu mesajul corespunzător de tip not-understood. Lista completă a parametrilor mesajelor utilizaţi în aplicaţie este dată în tabelul 8.1[2].
|
Categorie parametru |
|
|
performative |
Tipul actului de comunicare |
|
sender |
Emiţător; participant la conversaţie |
|
receiver |
Receptor; participant la conversaţie |
|
content |
Conţinutul mesajului |
|
reply-with |
Control conversaţie |
|
in-reply-to |
Control conversaţie |
Tabelul 8.1. Parametrii mesajelor FIPA ACL
Parametrul reply-with introduce o expresie ce va fi utilizată de agentul ce răspunde spre a-şi identifica mesajul. Parametrul in-reply-to denotă o expresie ce se referă la o acţiune precedentă pentru care mesajul în cauză este o replică (reply). Folosind aceşti doi parametri se pot construi conversaţii continue între agenţi.
8.1.2. Actul de comunicaţie de tip „Inform”
Începând cu această secţiune se va prezenta subsetul bibliotecii de acte de comunicaţie FIPA (FIPA CAL[3] utilizat de către aplicaţie.
Un mesaj de tip inform indică receptorului că o propoziţie dată este adevărată. Mesajul indică următoarele în legătură cu agentul emiţător:
Emiţătorul susţine că o anumită propoziţie este adevărată.
Emiţătorul intenţionează ca receptorul să ajungă să creadă că propoziţia este adevărată.
Emiţătorul nu crede că receptorul cunoaşte deja valoarea de adevăr a propoziţiei.
Ultima proprietate se referă la corectitudinea semantică a acţiunii de comunicaţie. Dacă un agent cunoaşte că o anumită stare a lumii există, anume că receptorul cunoaşte o anumită propoziţie, nu are sens ca el să încerce să aducă lumea în acea stare – adică, să îi comunice receptorului un fapt pe care deja îl cunoaşte. De notat că emiţătorului nu i se cere să stabilească dacă receptorul cunoaşte sau nu propoziţia în cauză.
Din punctul de vedere al receptorului, el va şti că emiţătorul doreşte ca el să îşi schimbe cunoştinţele în funcţie de propoziţia dată – hotărârea de a le schimba sau nu depinde de nivelul de încredere de care emiţătorul se bucură la receptor.
8.1.3. Actul de comunicaţie de tip „Request”
Emiţătorul îi cere receptorului să efectueze o anumită acţiune. O clasă importantă de astfel de acţiuni reprezintă realizarea de către receptor a unui alt act de comunicare.
Conţinutul mesajului este o descriere a acţiunii de efectuat, într-un limbaj pe care receptorul îl înţelege. Acţiunea poate fi orice fel de acţiune pe care emiţătorul este capabil de a o efectua. O utilizare importantă a actului request este construcţia de conversaţii compozite între agenţi, unde acţiunile ce fac obiectul cererii sunt la rândul lor acte de comunicare, cum ar fi inform.
8.1.4. Actul de comunicaţie de tip „Agree”
Semnifică acordul de a efectua o acţiune, posibil în viitor. Acordul are loc ca urmare a unei cereri anterioare de a efectua o acţiune. Agentul emiţător al acordului informează receptorul că intenţionează să efectueze acţiunea[4]. Propoziţia trimisă ca parte a mesajului indică setul de calificatori asociat de către agent acordului – spre exemplu, momentul în care acţiunea va fi efectuată.
Aplicaţia foloseşte mesajele de tip agree într-un mod nestandard, şi anume pentru a trimite direct rezultatele acţiunii solicitate. În acest fel, se elimină necesitatea unei secvenţe suplimentare în protocolul de interacţiune.
8.1.5. Actul de comunicaţie de tip „Refuse”
Actul de comunicaţie de tip refuse este o abreviere pentru negarea faptului că agentul poate efectua o acţiune şi declară motivul acestei stări de lucruri. Acest tip de act este efectuat când agentul nu poate satisface toate precondiţiile acţiunii de efectuat, fie implicite fie explicite. De exemplu, agentul nu cunoaşte informaţia solicitată, sau cererea a fost rău formată, anumiţi parametri necesari lipsind.
Agentul ce primeşte un mesaj de tip refuse va putea crede că:
Acţiunea nu a fost efectuată.
Acţiunea nu este fezabilă din punctul de vedere al emiţătorului mesajului de refuz.
Motivul cauzal al refuzului este reprezentat de o propoziţie ce face parte din conţinutul mesajului. Nu se garantează că receptorul va înţelege acest motiv; totuşi, un agent cooperant va încerca să explice în mod constructiv refuzul.
8.1.6. Actul de comunicaţie de tip „Failure”
Reprezintă acţiunea de a comunica unui agent faptul că efectuarea unei anumite acţiuni a fost încercată dar încercarea a eşuat.
Mesajul de tip failure este o abreviere ce informează că o acţiune a fost considerată fezabilă de către receptor, dar nu a fost efectuată dintr-un motiv dat. Agentul ce recepţionează un astfel de mesaj va putea crede că:
Acţiunea nu a fost efectuată.
Acţiunea este, sau era la momentul la care agentul a încercat să o efectueze, fezabilă.
Motivul cauzal al eşecului este reprezentat de o propoziţie ce face parte din conţinutul mesajului. Adesea, nu există multe lucruri pe care oricare dintre agenţi le-ar mai putea face pentru efectuarea acţiunii considerate.
8.1.7. Actul de comunicaţie de tip „Not-Understood”
Emiţătorul actului de comunicaţie de tip not-understood a recepţionat un act de comunicaţie pe care nu l-a înţeles. Pot exista mai multe motive pentru această stare de lucruri: agentul nu a fost proiectat pentru a procesa o anumită categorie de mesaje, sau aştepta în momentul respectiv un alt tip de mesaj. De exemplu, agentul urmărea un protocol predefinit în care secvenţele posibile de mesaje sunt predeterminate. Mesajul de tip not-understood indică emiţătorului mesajului original, cel care nu a fost înţeles, că nici un fel de acţiune nu a fost adoptată ca urmare a mesajului. Acest act poate fi de asemenea folosit în cazul general spre a informa un agent că o acţiune efectuată de el nu a fost înţeleasă de către emiţător.
Conţinutul mesajului include o propoziţie ce dă motivul eşecului în înţelegerea mesajului. Nu se garantează că acest motiv va fi înţeles de către agentul receptor. Cu toate acestea, un agent cooperant va încerca să explice neînţelegerea într-un mod constructiv.
8.2. Protocoale de comunicaţie
Protocolul de comunicaţie cel mai frecvent utilizat în cadrul aplicaţiei este protocolul de interacţiune de tip request. Acesta este reprezentat schematic în figura 8.2.1. Protocolul permite unui agent să solicite altuia efectuarea unei acţiuni. Participantul procesează cererea şi decide dacă să accepte sau să refuze cererea. Dacă decizia este un refuz, Participantul comunică un refuse.
În cazul în care condiţiile indică faptul că un acord explicit este necesar, Participantul comunică un agree. Odată ce a fost de acord cu cererea, Participantul trebuie să comunice fie:
Un mesaj de tip failure dacă eşuează în îndeplinirea cererii.
Figura 8.2.1. Protocolul de interacţiune de tip request
Un mesaj de tip inform dacă a îndeplinit cu succes acţiunea, cu două subcazuri: acţiunea nu are rezultate şi mesajul doar notifică Iniţiatorul de efectuarea ei – ramura inform-efectuat; respectiv acţiunea are rezultate şi mesajul le conţine – ramura inform-rezultate.
Uzual, mesajele ce fac parte dintr-o instanţă a acestui protocol se grupează în conversaţii pe baza unor identificatori.
Aplicaţia utilizează o versiune simplificată a acestui protocol, prezentată în figura 8.2.2. În această versiune, un al doilea mesaj trimis de către Participant devine inutil. Astfel, dacă acţiunea nu este un refuz, pot exista două cazuri:
Participantul eşuează în îndeplinirea ei, caz în care trimite un failure conţinând motivul eşecului.
Participantul reuşeşte în îndeplinirea acţiunii, caz în care trimite un agree conţinând rezultatele ale acţiunii, dacă acestea există. Dacă nu, conţinutul mesajului este vid.
Figura 8.2.2. Protocolul simplificat de interacţiune de tip request
Acest protocol redus permite o comunicare mai eficientă şi mai rapidă între agenţi reducând încărcarea reţelei.
Cel de-al doilea protocol de comunicaţie utilizat este extrem de simplu[5]: un agent informează un altul despre o anumită stare de lucruri printr-un mesaj de tip inform. Nici un fel de răspuns nu este aşteptat; o conversaţie nu are loc. Reprezentarea schematică a acestui tip de protocol este dată în figura 8.2.3.
Figura 8.2.3. Protocolul de interacţiune de tip inform
9. Model de referinţă societate digitală de agenţi
Modelul de referinţă pentru o societatea digitală de agenţi oferă o structură normativă cu care agenţii FIPA sunt compatibili să existe şi să funcţioneze. Combinaţi cu ciclul vieţii unui agent formează contexte logice şi temporale pentru creaţie, funcţionare a agenţilor.
Platforma agent conţine:
· Facilitator (Directory Facilitator – DF)
· Sistem de administrare a agentului (Agent Administration System – AAS)
· Canal de comunicaţie interagent (Agent Communication Channel – ACC)
· Platformă de transport a mesajelor interne (Internal Message Transport Platform – IMTP)
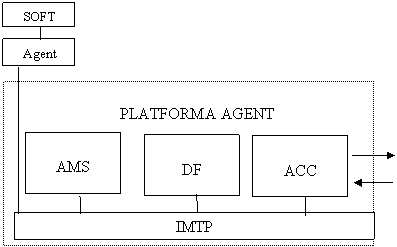

Figura 9.1. Platforma agent
9.1. Facilitatorul
Facilitatorul, denumit în cele ce urmează prin acronimul DF[6], este componenta platformei agent care furnizează agenţilor serviciul director, de tip pagini aurii. DF este custodele de încredere al directorului de agenţi – „de încredere” în sensul în care trebuie să facă efort în vederea menţinerii unei liste de agenţi precise, complete şi actuale. DF are de asemenea obligaţia de a furniza informaţia cea mai recentă despre agenţii din directorul său pe baze nediscriminatorii tuturor agenţilor autorizaţi. Cel puţin un DF trebuie să rezide pe platforma agent, dar mai mulţi DF pot exista iar aceştia se pot înregistra între ei formând federaţii.
Fiecare agent ce doreşte să îşi facă publice serviciile altor agenţi va găsi un DF corespunzător şi îi va solicita acestuia înregistrarea ca furnizor al serviciilor respective[7]. Agentului ce se înregistrează nu i se impun nici un fel de obligaţii suplimentare – spre exemplu, el poate refuza o cerere ce se referă la un serviciu pe care l-a publicat prin intermediul unui DF. Mai mult, DF nu poate garanta validitatea sau precizia informaţiilor ce au fost înregistrate în directorul propriu, nici controla ciclul de viaţă al unui agent. De-înregistrarea are drept consecinţă anularea obligativităţii DF-ului de a furniza informaţii referitoare la agentul ce se de-înregistrează.
Un agent va solicita informaţii DF-ului prin operaţii de căutare. DF nu garantează validitatea informaţiilor furnizate ca răspuns al unei cereri de căutare, deoarece nu impune restricţii asupra informaţiilor ce sunt înregistrate în director. Totuşi, DF poate restricţiona accesul la informaţiile aflate în director şi verifica permisiunile de acces pentru agenţii ce emit solicitări către el[8].
9.1.1. Funcţii de gestiune oferite de către facilitator
Înregistrare, register. Execuţia acestei funcţii are ca efect înregistrarea unui nou agent[9] în baza de cunoştinţe a DF-ului.
De-înregistrare, deregister. Un agent poate să de-înregistreze un agent spre a-l îndepărta ca furnizor al anumitor servicii din director[10].
Un agent va putea căuta, search, după anumite servicii spre a solicita informaţii DF-ului. O căutare reuşită va întoarce unul sau mai mulţi agenţi care satisfac criteriile de căutare[11].
9.1.2. Federaţii de facilitatori
DF încorporează un mecanism de căutare care efectuează căutarea întâi local, extinzând-o apoi la alţi DF dacă acest lucru este permis. Mecanismul implicit de căutare este o căutare mai întâi în adâncime în federaţia de DF. Federarea DF se poate realiza prin înregistrarea reciprocă a DF-urilor. Pentru scopuri specifice, constrângeri opţionale pot fi aplicate căutării, descrise în tabelul 9.1.2.1., cum ar fi de exemplu numărul maxim de rezultate furnizate.
În momentul în care un DF recepţionează o cerere de căutare, el va determina dacă se impune propagarea căutării în federaţia de DF. Vor fi propagate doar cererile de căutare pentru care valoarea parametrului max-depth este mai mare decât 1, iar valoarea parametrului search-id nu este identică cu vreuna a unei cereri de căutare deja procesate. Dacă cererea este propagată, propagarea trebuie să respecte următoarele reguli:
Nu va schimba valoarea parametrului search-id, care trebuie de asemenea să fie unică.
Înainte de propagare, valoarea parametrului max-depth va fi decrementată cu 1.
|
Descriere |
Prezenţă |
Tip |
|
|
max-depth |
Adâncimea maximă la care o căutare se poate propaga în federaţia de DF. O valoare negativă indică faptul că solicitantul este dispus să permită căutării să se propage în toată federaţia. |
opţional |
integer |
|
max-results |
Numărul maxim de rezultate returnate de căutare. O valoare negativă indică faptul că solicitantul este dispus să primească toate rezultatele disponibile. |
opţional |
integer |
|
search-id |
Un identificator unic global al căutării. |
opţional |
string |
Tabelul 9.1.2.1. Constrângeri de căutare
9.1.3. Excepţii
Următoarele reguli sunt adoptate spre a alege actul de comunicaţie potrivit ce va fi trimis în răspunsul unei cereri de acţiune de gestiune care generează o excepţie:
Dacă actul de comunicaţie nu este înţeles de către agent, replica va fi una de tip not-understood.
Dacă acţiunea solicitată nu este suportată de către agentul receptor, actul de comunicaţie este refuse.
Dacă acţiunea este suportată de către agentul receptor dar emiţătorul nu este autorizat să o solicite, actul de comunicaţie este refuse.
Dacă funcţia solicitată este suportată de către receptor şi agentul client este autorizat să o solicite, dar funcţia este sintactic sau semantic incorectă, actul de comunicaţie este refuse.
Dacă funcţia este sintactic şi semantic corectă, dar în timpul execuţiei se ivesc condiţii ce împiedică ducerea acesteia la bun sfârşit, actul de comunicaţie este failure[12].
În toate celelalte cazuri replica va fi un agree conţinând eventualele rezultate ale cererii.
Tabelele de mai jos sintetizează tipurile de excepţii ce pot apărea în recepţionarea şi tratarea cererilor la DF.
|
Nume câmp[13] |
Tip câmp |
Descriere |
|
unsupported-act |
string |
Agentul receptor nu suportă actul specific de comunicaţie; câmpul identifică actul de comunicaţie în cauză. |
Tabelul 9.1.3.1. Excepţii de tip not-understood[14]
|
Nume câmp |
Tip câmp |
Descriere |
|
unsupported-function |
string |
Agentul receptor nu suportă funcţia specifică; câmpul identifică numele funcţiei ce nu este suportată. |
|
missing-argument |
string |
Un argument obligatoriu al funcţiei lipseşte; câmpul identifică numele argumentului ce lipseşte. |
|
invalid-argument[15] |
string |
Un argument al funcţiei are o valoare invalidă; câmpul identifică numele argumentului invalid. |
Tabelul 9.1.3.2. Excepţii de tip refuse
|
Nume câmp |
Tip câmp |
Descriere |
|
already-registered |
string[16] |
Agentul emiţător este deja înregistrat ca furnizor al serviciului dat în directorul agentului receptor. Câmpul conţine un mesaj ce descrie excepţia. |
|
not-registered |
string[17] |
Agentul emiţător nu este înregistrat ca furnizor al serviciului dat în directorul agentului receptor. Câmpul conţine un mesaj ce descrie excepţia. |
Tabelul 9.1.3.3. Excepţii de tip failure